I just bought the software and it worked perfectly on the first run. It could use a few features, though.
I'd like to be able to remove the ">>" at the start of lines.
Recognition of audio gaps. The file I tried it on has no audio for the first 20 seconds, but it starts the subtitle at 0:00:00. It also leave t he subtitles up during gaps instead of going blank until the next speaking portion
Hearing impaired subtitles, i.e. "[Music]" "[Screams]" "[Engine Sounds]"
Batch queueing. I would like to throw in a more than one file and walk away while it works.
The option to auto save to SRT.
Edit: I think I spoke to soon about how good this is at transcribing. I'm running into a problem where it's repeating text hundreds of times over.
The AI model really doesn't understand the stop and start of speech.
I'm another user, and I started using it to create subtitles from videos that I downloaded from YouTube, etc. These video files did not come with a subtitle file.
It does create the hearing‑impairing stuff, like music, I noted.
But it would be such a nice upgrade if it could work with more than one file and automatically save.
I recently purchase this software and installed in windows. It doesn't work. It stops transcribing in middle of the video. Could you please process the refund?
This tool is incredible, however I have noticed some quirks. I've been using this tool to create subtitles for media that doesn't have any. The issue I've encountered is the timing of the subtitles. Sometimes some of the dialogue will appear prematurely before the sentence is said. Or if if there's context like [Music], [Screams], etc, the caption will just sit there indefinitely until there's new dialogue. I'm not sure if it's overcompensating the timing based on the transcription model? I've been aiming for maximum accuracy.
Same as one of the comments from a month ago, I would like to try the software demo Windows version but cannot download it. I got the itch.io app, signed up for an account and searched but could not find it there. Nothing even close to the title comes up. Any help?
I have a Co pilot Surface Pro 11 with a Snapdragon ARM CPU, and I’m encountering the following issue when trying to transcribe audio or video files:
Error message: “An error occurred when trying to transcribe the file. ERROR CODE: 2”
I’ve tested several different files, and none of them work on the Snapdragon device. However, when I try the exact same files on my Intel-based Surface, transcription works without any issues.
Could you please look into adding support for the Snapdragon variant,If you can do this I will Definitely buy this program?
I see where the issue is. Basically Private Transcriber Pro uses optimised x86_64 instructions to speed up the transcription process. Since ARM doesn't have those instructions, it just crashes.
There might be support for Windows on ARM in the future, but it is low in the priority, so it's basically an unsupported platform at the moment.
Good morning, I would like to try the app before purchasing it, so I have tried to download the demo version several times, but I cannot complete the download because I get the error message ‘the file is not available on the site’. What should I do? Thank you.
The files are hosted at itch.io, which are not managed by me. Here is a post from them explaining what you can do if you're having issues with the downloads: https://itch.io/post/597689
I am a user-I have to say that this program is shockingly good for what it does. I have a few MP4 videos that I needed to create SRT subtitles for, and I have a few options: this program and two others. I find that my setup(desktop, i9, 128 G of RAM and RTX 4090) works very quickly and accurately with this program, and for the price, it's really amazing.
So, when I open the app it shows only this blank screen and it won't let me drag any files in for transcription. Any ideas? My apologies if this issue has already been addressed earlier in the comments. Thanks
Sometimes the model gets confused if there are other sounds as well. Some things you could try are basically choosing a different model (select one that is more accurate or one that is faster), and also you could split the input into smaller sections, specially at the times that it is getting these issues.
Very happy with your program, thanks again! Even though it's working well most of the time, I have a few videos where I just get a long list of [speaking in French] or even [speaking on foreign language] even though it's all French, and a very clear one with no accent (documentaries videos). A bit hard to understand these fails! I also tried another documentary with mixed languages used (with interviews for instance), and I can confirm that German is not being picked up for some reason. Also it doesn't look like it's able to pick up different languages in 1 single file - it was probably not meant to be used that way but it could be super nice if it was possible!
I've just released v2.5.1, which adds the ability to manually set which language the audio is in. This should help you when the automatic language detection doesn't work properly. Note that it does only work with one language per input file.
Awesome - just tested it and it seems to solve the issue indeed. One thing you might want to know though, is the fact the drag and drop functionality doesn't work anymore (a "forbidden/stop" icon replaces the mouse cursor). I'm on windows 10.
Also, I still have 1 issue with 1 specific video where the automatic transcript stops (it starts repeating the same line 15 times then nothing, despite of 20mins of video left - settings change with the accuracy slider didn't help). But I think I identified a pattern - the previous video where French/no dialog was picked up at all started with a rather strong background music. But it's now picked up properly when French is forced in the settings. That other video I just mentioned picks up the French properly but stop at a moment when again, the video has a stronger music background before the talking resumes. Could the model struggle when unusual music type/noise level is heard? Nothing that I really need to be fixed to be honest (I solved the issue by editing the bit with the music out of the video) but it's just food for thoughts if you ever see someone else is having similar issues and you fancy working on a solution.
Hello! I found your app from a post about qualitative transcripts on Reddit. I am just wondering if it is possible to have the .txt have timestamps similar to the .srt version. Additionally, it would be great to be able to download/copy the table that is created in the transcriber for easier upload to programs like NVivo. Thanks!
Hey dude - awesome initiative here, online subscription based services are hell. Happy to support your work. But before I buy, 2 questions: - Does it support French? - I suspect a lot more people would go for this tool if it was a little bit more than a "subtitles maker". Do you think there would be any way to have an option where the produced result is more formatted like normal text, rather than something with a timecode for each line? To have both options would be incredible
Yes, it should be able to translate French. You can download the demo and see how it works. At the moment it automatically detects the language, and in a new version it will allow you to manually specify the language as well in case there is any issues with the automatic detection.
Normal text is already supported. You have the option of saving the result as either subtitles (.srt) or normal text (.txt). You can also test this in the free demo.
Download the free demo and see how it works for you!
With one subscription, can I download both for PC and Mac and test which GPU is faster for me?
I have to transcribe hours and hours of someone basically wearing a wire. There are sometimes hours of nothing. Will the app be able to speed through those parts?
There's no subscription, you pay once and get to use it forever, with free updates as well.
Both versions, macOS and Windows, are included in the price. You can run them on any number of computers you have.
The best way to test how long it takes is to simply test with the free demo. You can download it for macOS and Windows. The demo basically does the same as the full version, but the output is changed once it finishes, every other line of the transcription is changed to a demo sentence.
Unfortunately, automatic speech recognition does not work for me. I have tried all models, various variants of audio and video files. Also in the metadata my language German is set correctly. But it is never recognized. It is transcribed either in Russian, Chinese, English, etc., but no German. Would it be possible to simply add a menu in the settings where you can select your language? Can you please improve that, that would be very helpful. Use MacOS 14.7.6.
For information: In the meantime, I was able to try out and test the software under MacOS 15.5 (Sequoia) and found that it is not possible to export the transcriptions as "srt" or "txt". No export dialog opens for the two menu items! Please check compatibility. Thank you very much!
I've just released v2.5.1, which adds the ability to manually choose the language of the input audio. This should fix the issue when the automatic language detection doesn't work properly.
I haven't tested it with that particular card, but it should work with most modern ones. The easiest way to check would be to run the demo with the GPU option set.
I can't deny that the program is excellent. However, I'm experiencing an issue. After doing 2–3 transcriptions, the program shuts down by itself. I'm working with .mp4 files, but the problem doesn't seem to be with a specific file, because the same files that cause the program to crash work fine when I open them again
Yes I am also after transcribing multiple mp3 files. I don't care if it takes a while to do so but I don't want to add file one at a time. Other than that I really like the program.
Hello! I bought the software a couple of days ago, but I am just testing it today (I replied to you on reddit!). The file that I am trying to transcribe was a DVD that I converted to mp4 with HandBrake, and clocks at about 1 hour, 20 minutes approx. 389mb.
The file is recognized by the software, and it says in the bottom "Transcribing filename.mp4". However, it doesn't go past 0%. And after 5 minutes or so, the text that says "Transcribing ..." disappears. But the progress bar still shows 0% as if there was a file loaded.
I then tried without GPU acceleration on options, and the text with the file name remains, but it still doesn't show any progress. Is that to be expected with a file of that size?
My notebooks is kind of old, a 2015 ThinkPad with an intel i7-5600U. Maybe it is expected to be that slow? It has been running for 1 hour now, and it still shows it at 0%. Maybe a way to know if it is running, or stopped and should be loaded again.
Thank you for any help! And please tell me what else should I report. Cheers!
The first thing that I would do in your case is to test with a smaller video or audio, one that is one minute for example. Just drag and drop it and see how long it takes your system to transcribe it. Most probably it will take longer than that one minute since the CPU is from 2015, so it will be much slower than a more modern machine.
Now that you know how long it roughly takes (for example double the time, or ten times, whatever it is), you will be able to get a rough idea of how long it would take on your machine to transcribe that file of 1 hour 20 minutes.
Usually I would recommend using the GPU option, but for a machine that old, probably it will cause more problems than what's worth. That's one of the reason why I added this option, to be able to skip the GPU if there are any issues. So, try it without the GPU, that's the most reliable way.
Now, after you have an idea of how long it would take, run it, and leave it there doing its thing. You can check that the application is working properly by opening up the Task Manager. You will see the name of the application and the CPU usage. You can open the Task Manager in Windows by pressing Ctrl + Shift + Esc.
I would leave it overnight running, because my guess is that it would need a few hours to process a file that is 1 hour and 20 minutes. Modern machines need about the same amount as the input, so a decade old machine would need quite a bit more.
I found a bug (i think) in the new 241 version. When selecting the most accurate (biggest) model, it outputs random garbage text for quite a while, then after a few minutes into the video it starts picking up the correct language, and translates it correctly. On the default middle setting it translates the video fast and correct! PS: on the most accurate setting it also often crashes the app at the very end of loading the video, before it begins transcribing it (.mp4 720p vids). The video file itself is not the issue, since the middle setting does the whole video correctly without crashing. The program has no error-log when it crashes, so I cant be helpful in providing that info, so maybe an idea to implement such a log in the future? (see image below for results)
This is something that comes from the model itself, so I will have a proper look at it. Maybe I will need to expose some extra settings that will be available as "Advanced settings" to make it work properly.
Hey! Great work! The new GPU version (v241) is waaay faster than the older (v214) (PS: important question below the picture, so view the rest of this post)
Is it possible to have it translate to other languages than "English" ? I assume the AI is first transcribing the audio to text in original language, then the AI translates the sentence to English also using the AI, right?
If that is the case then a dropdown list of languages the AI supports would make it possible to translate a german video into norwegian subtitles, or as now getting the german video into an english subtitle. Can you possibly add this? Or would it be more complicated than I think?
Yeah, the GPU enabled version is much faster. Glad you got this update.
In terms of the translation, it actually doesn't work exactly like that. The model itself basically only does transcription to the same language. The model just has a "bonus" feature that allows direct translation from audio to English, no intermediary text to translate.
Having a full translation from any language to any other language is outside the scope for this app. If there's interest, I could publish an independent app that does full translation of subtitles and text from any language to any other one, which would complement this app.
An independent app that does full translation of subtitles and text from any language to any other one, is indeed very interesting! It should of course have GPU support as well as CPU support. It would be truly awesome if it could also have the support for converting .SRT into .VTT (WebVTT). That format has a header (3 lines) and all dots in the time-stamp unlike .SRT that has one comma in their timestamp. It also has the ability to place text at different positions on the screen, but the normal/default captions/subs position we're all used to is: align:middle size:95% line:95 The incrementing block-numbering before each block of "timestamp+position+text" as one has in .SRT, is optional in .VTT Example (WebVTT) .VTT Subtitle/Captions File:
WEBVTT Kind: captions Language: en
00:00:00.000 --> 00:00:08.380 align:middle size:95% line:95 So how do you make a web page that looks like this where you have a video and it shows a
00:00:08.380 --> 00:00:14.680 align:middle size:95% line:95 nice picture where you can put the title of the video or information about what the video
00:00:14.680 --> 00:00:23.560 align:middle size:95% line:95 is about and it has obviously this video player which has this hamburger menu over here
So as you see, very similar to the .SRT format, but the benefit of this format is that it can be used with HTML5 players, so you can upload it directly to youtube (or other services supporting sub/caption) and on your own homepage, if you need video with subtitles. PS: I've made a python script doing this .SRT to .VTT conversion, that i can share it with you, if need be. (not C++ code, but just as easy to read, he he)
Could you please add the following features: translation of SRT subtitles into other languages, an option to adjust the number of words displayed per line, and the ability to keep complete sentences on a single line if desired? Additionally, it would be great to include an AI-powered summarization function. Thank you.
Very nice app! Love the idea of a fast offline transcriber/translator! I am currently testing the demo, and after doing so I paid and bought this software!
I have two questions I'd like to ask: Do you have an approx. e.t.a (month/year) for when the GPU / CPU switching possibility will arrive in an updated version?
And also I wonder if the app is temporarily writing the text it translates from speech to txt, to a txt file, like every minute or so, just in case the app might crash for unforeseen reasons. So that you may read some of it, if you have to restart the procedure due to a random app-crash?
I will integrate GPU support in the next update, so it shouldn't be too long.
The app keeps the transcription in memory. In theory I could add an "autosave" of the transcription if the app is interrupted for any reason, before exiting. I could add this as well for the next update.
Hi tok-ai, can you describe the environment, such as your OS (Windows, macOS, Linux), and the type of audio file you are using? If it's possible to share with me an audio file that is causing you this issue I could try to replicate the problem. You can msg me directly on reddit (/u/samontab)
Hey Samontab ! PrivateTranscriber looks quite awesome. However, I find it very hard to evaluate with the demo version whether the app provides an accurante transcription of the audio I've submitted. Could it be possible to either A/ change the demo version to gather one every two minutes, rather than by segments of 10 secs ; or B/ to send you ONE audio file to get the full transcription ? I do have the feeling that would be more helpful to evaluate. Many thanks ! All best.
They are both completely independent versions so you only need one, v1.5.2 has more models so that's why it's larger. It includes everything you need to run it.
why is it translating English to welsh? and copying the same thing over and over after hours of waiting for it? "Mae'n gwaith unrhyw." and other welsh phrases/sentences over and over? how do i fix this? some of the other transcripts have been fine..
Since it is an AI transcription, it might not get it right all the time, and sometimes you might see what you describe.
You can try fixing it by using a different model, either a more accurate one or a faster one. You can select this in Edit->Settings under Transcription Model
Love the app, works fast and remarkably well for the processing speed! I normally use whisperx with pyannote for segmentation and diarization but that process is not well suited to rapidly transcribing video in low latency distribution! My primary use case is to scan video for obscene language prior to general distribution. The drag and drop pipeline with post processing cleanup grid has cut my worktime in half! Quick question, Is there any way to inject into the translation pipeline so I could add Speaker Diarization?
This is fantastic, thank you for providing this. I'm deaf, tryibng to study from videos and it's driving me cray-cray!
Is there way to hook this into system sound so that I can get a rolling transcription of videos that i can'f download or get the URL of? As a student I use Learning Mangement Systems that embed videos but lock out pretty much everything except PLAY!
Google translate (Engish - to - English) is what I'm using now, but i have to pause, screen capture, Google Lens or Snagit to get text, dump in Notepad to clean out non-text, copy to asy Word or OneNote and aaarrrrgh! There has to be a simpler way!
Hi Wad Mabbit Society, happy to hear you liked this software.
At the moment, it can only transcribe media files, not directly in real time from the microphone.
One option you can do is to record the sounds coming from your system, and then feed that recording into the software. This will get you the best quality, as real time transcription requires a simpler model, and is also not currently planned for the short term at least.
Hi rebork5555, you can download a demo of the program to see how it works. Just click on the Download button next to PrivateTranscriberPro DEMO v1.5.2.
Hi Rebork5555, you can keep the transcription in Spanish by selecting "Keep original language" in the Settings menu.. You can see that option by going to the Edit menu, then clicking on Settings. You'll see something like this:
You are absolutely correct Kijkeenolifant, the current version only uses CPU. In a future version there will be an option to accelerate it with your GPU.
The point was to first make it available to everyone, and then making it better over time with new releases. Anyone that buys it will have access to future versions anyway, forever!
Nice work on the application. Great all in one lightweight package. Would it be possible to include the larger models in the application as well? That's the only downside for me at the moment compared to installing the normal way.
Thanks Kijkeenolifant, great to hear you liked it.
What you say is a valid point. I originally planned to include all the models in the application, but ended up with a file that is way larger than itch.io's maximum allowed download file size (1GB), so I ended up including only a subset of them to make the application pass this constraint.
Having said that, it looks like I can manually request itch.io for a larger maximum file size, so I will update this tool if they increase this limit.
I ended up discovering a different way of uploading files (butler) which is much nicer and doesn't have the 1GB restriction. So, as promised, I just updated the app to include five different model sizes, which are now available in v1.5.2.
I didn't want to include all the 3 versions of the large model as the download is already at about 5GB so I only added large-v1 which seems to be the one with least amount of issues in general, but if you want to use any of the other 2 large models (v2 or v3), you can simply copy the model you want to use to the models folder and change its name to large-v1 and it will use that model instead when you select the most accurate setting.
← Return to tool
Comments
Log in with itch.io to leave a comment.
I just bought the software and it worked perfectly on the first run. It could use a few features, though.
Edit: I think I spoke to soon about how good this is at transcribing. I'm running into a problem where it's repeating text hundreds of times over.
The AI model really doesn't understand the stop and start of speech.
I'm another user, and I started using it to create subtitles from videos that I downloaded from YouTube, etc. These video files did not come with a subtitle file.
It does create the hearing‑impairing stuff, like music, I noted.
But it would be such a nice upgrade if it could work with more than one file and automatically save.
I am just a very happy user. Very, very happy.
p.s. https://sites.google.com/site/tsdarkness/batchsubtitlesconverter I use this program to correct subtitle files when there are errors in them.
Both of these programs are worth every penny, and I am grateful they set the price to be affordable because I want to support them.
I recently purchase this software and installed in windows. It doesn't work. It stops transcribing in middle of the video.
Could you please process the refund?
Hey, the demo works exactly in the same way that the full version works, just with some limitations.
If you tried the demo, and it didn't work, then you should not have bought it.
Also, the software works, as you can see from hundreds of happy paying customers.
You can absolutely start a refund process with itchio, but please be honest.
This tool is incredible, however I have noticed some quirks. I've been using this tool to create subtitles for media that doesn't have any. The issue I've encountered is the timing of the subtitles. Sometimes some of the dialogue will appear prematurely before the sentence is said. Or if if there's context like [Music], [Screams], etc, the caption will just sit there indefinitely until there's new dialogue. I'm not sure if it's overcompensating the timing based on the transcription model? I've been aiming for maximum accuracy.
Same as one of the comments from a month ago, I would like to try the software demo Windows version but cannot download it. I got the itch.io app, signed up for an account and searched but could not find it there. Nothing even close to the title comes up. Any help?
Hi vbanci,
You can simply click on Download right here, no need to search for anything else...
Here's a screenshot of where to click:
Yesterday it didn't but today it works! Thanks.
I have a Co pilot Surface Pro 11 with a Snapdragon ARM CPU, and I’m encountering the following issue when trying to transcribe audio or video files:
Error message:
“An error occurred when trying to transcribe the file. ERROR CODE: 2”
I’ve tested several different files, and none of them work on the Snapdragon device. However, when I try the exact same files on my Intel-based Surface, transcription works without any issues.
Could you please look into adding support for the Snapdragon variant,If you can do this I will Definitely buy this program?
Hi hardworking323,
Thanks for the detailed description of the issue.
I see where the issue is. Basically Private Transcriber Pro uses optimised x86_64 instructions to speed up the transcription process. Since ARM doesn't have those instructions, it just crashes.
There might be support for Windows on ARM in the future, but it is low in the priority, so it's basically an unsupported platform at the moment.
I didn't specify that the version I would like to download is for Windows.
Good morning, I would like to try the app before purchasing it, so I have tried to download the demo version several times, but I cannot complete the download because I get the error message ‘the file is not available on the site’. What should I do? Thank you.
Hi Faboineag,
The files are hosted at itch.io, which are not managed by me. Here is a post from them explaining what you can do if you're having issues with the downloads: https://itch.io/post/597689
I hope this helps.
I am a user-I have to say that this program is shockingly good for what it does. I have a few MP4 videos that I needed to create SRT subtitles for, and I have a few options: this program and two others. I find that my setup(desktop, i9, 128 G of RAM and RTX 4090) works very quickly and accurately with this program, and for the price, it's really amazing.
Thank you for the update!!!
So, when I open the app it shows only this blank screen and it won't let me drag any files in for transcription. Any ideas? My apologies if this issue has already been addressed earlier in the comments. Thanks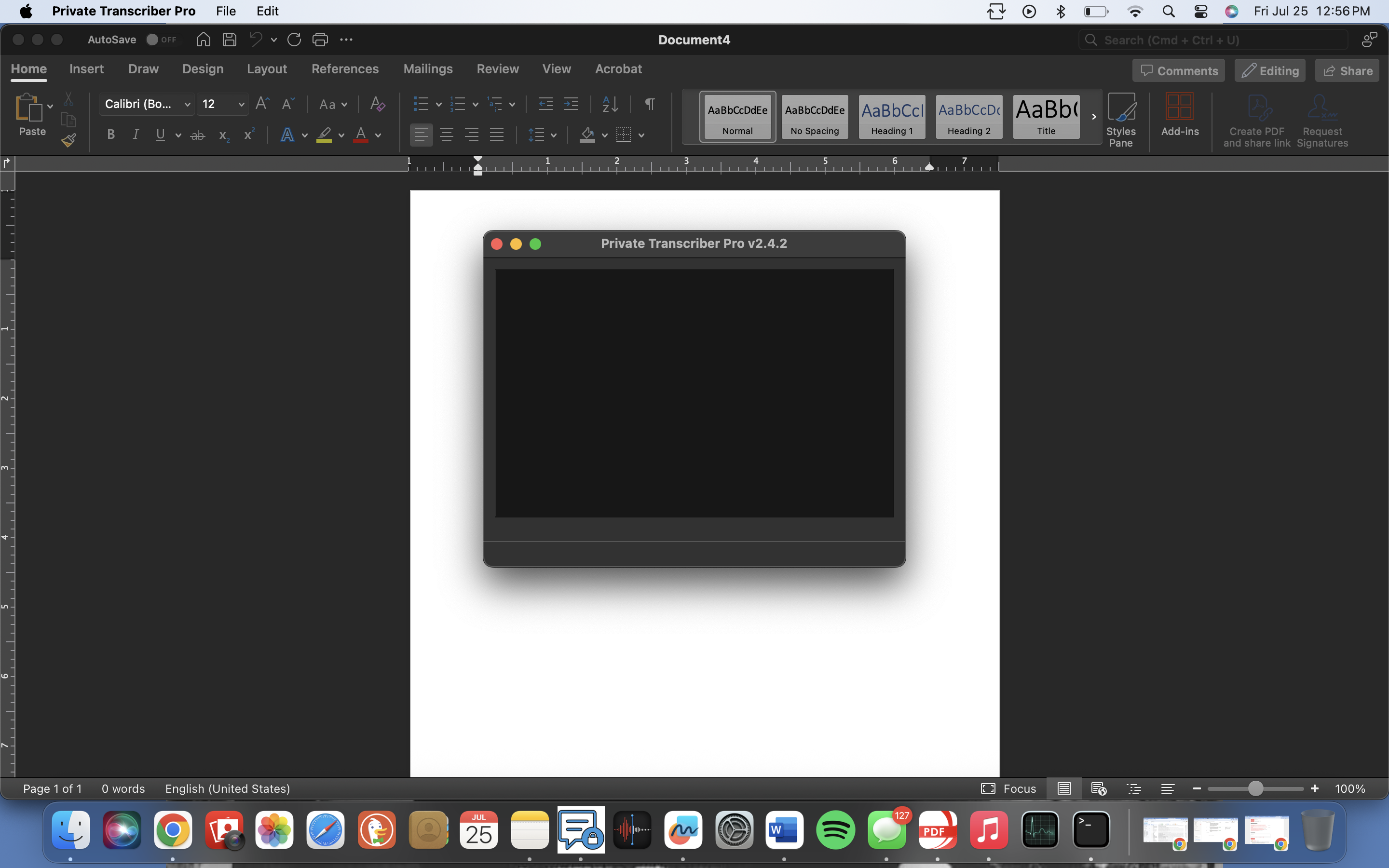
Hi michellekrollerlaw,
Thanks for bringing this to my attention.
I just tested this on my macOS machine with Sequoia 15.5 and you're absolutely right!.
This is curious as I recently published v2.4.2 to fix another GUI issue on macOS and it was definitely working fine then.
Anyway, I will fix this issue for the next release which should be coming soon!
Hi michellekrollerlaw,
I've just released v2.5.1, which fixes the issue you were having in macOS.
Thanks for this it's really great, can you make a Linux version? Ubuntu? Fine with CLI even with input.mp3 output.txt option
Hi soulrider4ever,
You can use the Windows version in Linux with wine
Having issues with the 2.4.1 on Windows where it will repeat the same line over and over again, example: 15 instance of a row of:
I have switched with both of them.
I have switched with both of them.
I have switched with both of them.
I have switched with both of them.
I have switched with both of them.
I have switched with both of them.
I have switched with both of them.
I have switched with both of them.
I have switched with both of them.
I have switched with both of them.
I have switched with both of them.
I have switched with both of them.
I have switched with both of them.
I have switched with both of them.
I have switched with both of them.
I have switched with both of them.
I have switched with both of them.
whether it's translated to English or left untranslated (in Swedish) -- how would I go about fixing that?
Hi ultracolathompson,
If you experience some of those issues, probably the simplest way to fix it is to select a different model, either a more accurate or a faster one.
Have done this several times and still wound up with the same choppy result. Is time of video a potential issue?
Hi ultracolathompson,
Sometimes the model gets confused if there are other sounds as well. Some things you could try are basically choosing a different model (select one that is more accurate or one that is faster), and also you could split the input into smaller sections, specially at the times that it is getting these issues.
Hope that helps!
Very happy with your program, thanks again! Even though it's working well most of the time, I have a few videos where I just get a long list of [speaking in French] or even [speaking on foreign language] even though it's all French, and a very clear one with no accent (documentaries videos). A bit hard to understand these fails! I also tried another documentary with mixed languages used (with interviews for instance), and I can confirm that German is not being picked up for some reason. Also it doesn't look like it's able to pick up different languages in 1 single file - it was probably not meant to be used that way but it could be super nice if it was possible!
Hi jairoaf,
Yes, the automatic detection uses the start of the audio and sometimes it might guess incorrectly.
I am preparing a new version that will allow the user to select the language manually as well, so it should fix this issue.
Hi jairoaf,
I've just released v2.5.1, which adds the ability to manually set which language the audio is in. This should help you when the automatic language detection doesn't work properly. Note that it does only work with one language per input file.
Awesome - just tested it and it seems to solve the issue indeed. One thing you might want to know though, is the fact the drag and drop functionality doesn't work anymore (a "forbidden/stop" icon replaces the mouse cursor). I'm on windows 10.
Also, I still have 1 issue with 1 specific video where the automatic transcript stops (it starts repeating the same line 15 times then nothing, despite of 20mins of video left - settings change with the accuracy slider didn't help). But I think I identified a pattern - the previous video where French/no dialog was picked up at all started with a rather strong background music. But it's now picked up properly when French is forced in the settings. That other video I just mentioned picks up the French properly but stop at a moment when again, the video has a stronger music background before the talking resumes. Could the model struggle when unusual music type/noise level is heard? Nothing that I really need to be fixed to be honest (I solved the issue by editing the bit with the music out of the video) but it's just food for thoughts if you ever see someone else is having similar issues and you fancy working on a solution.
Thanks though! I'm happy with the update!
Hello! I found your app from a post about qualitative transcripts on Reddit. I am just wondering if it is possible to have the .txt have timestamps similar to the .srt version. Additionally, it would be great to be able to download/copy the table that is created in the transcriber for easier upload to programs like NVivo. Thanks!
Hi cmbruse,
I am not familiar with the NVivo program, but if there is any other standard output that would be useful, then I could have a look at it.
Thanks. These are the formats that we have to upload to NVivo: https://help-nv.qsrinternational.com/15/mac/Content/files/import-audio-video-tra..., so if you were able to have one of these formats as your output, you'd gain a huge qualitative researcher following! This is a gap for us in using the program.
Great, thanks for the link cmbruse.
I will add that format in a future version.
Hey dude - awesome initiative here, online subscription based services are hell. Happy to support your work. But before I buy, 2 questions:
- Does it support French?
- I suspect a lot more people would go for this tool if it was a little bit more than a "subtitles maker". Do you think there would be any way to have an option where the produced result is more formatted like normal text, rather than something with a timecode for each line? To have both options would be incredible
Hi Jairoaf,
Thanks for the nice words.
Yes, it should be able to translate French. You can download the demo and see how it works. At the moment it automatically detects the language, and in a new version it will allow you to manually specify the language as well in case there is any issues with the automatic detection.
Normal text is already supported. You have the option of saving the result as either subtitles (.srt) or normal text (.txt). You can also test this in the free demo.
Download the free demo and see how it works for you!
Thanks! I pulled the trigger after trying the demo - amazing program!
Hello, does it support transcribing in Indonesian?
Hi yahyayasin,
Yes, Indonesian should be fine. You can always download the free demo and see how it performs with your files.
With one subscription, can I download both for PC and Mac and test which GPU is faster for me?
I have to transcribe hours and hours of someone basically wearing a wire. There are sometimes hours of nothing. Will the app be able to speed through those parts?
Hi frymeapples,
There's no subscription, you pay once and get to use it forever, with free updates as well.
Both versions, macOS and Windows, are included in the price. You can run them on any number of computers you have.
The best way to test how long it takes is to simply test with the free demo. You can download it for macOS and Windows. The demo basically does the same as the full version, but the output is changed once it finishes, every other line of the transcription is changed to a demo sentence.
Unfortunately, automatic speech recognition does not work for me. I have tried all models, various variants of audio and video files. Also in the metadata my language German is set correctly. But it is never recognized. It is transcribed either in Russian, Chinese, English, etc., but no German. Would it be possible to simply add a menu in the settings where you can select your language? Can you please improve that, that would be very helpful. Use MacOS 14.7.6.
Hi Mirko66,
Yes it can be done.
I will add this on the next update, thanks for mentioning this.
Thanks!
For information: In the meantime, I was able to try out and test the software under MacOS 15.5 (Sequoia) and found that it is not possible to export the transcriptions as "srt" or "txt". No export dialog opens for the two menu items! Please check compatibility. Thank you very much!
Hi Mirko66,
Good catch, I just tested this on macOS 15.5 and you're right, it doesn't open the dialogs (seems to be a bug in the underlying GUI library, Qt).
I just uploaded an updated version for macOS that fixes this (v2.4.2).
Thanks for the quick update, now the export in MacOS 15.5 works fine
I'm already waiting for the upcoming update when the menu item language selection is added so that it can be transcribed in German.
As mentioned before, I've just released v2.5.1, which allows you now to choose the language manually.
Hi Mirko66,
I've just released v2.5.1, which adds the ability to manually choose the language of the input audio. This should fix the issue when the automatic language detection doesn't work properly.
Thank you samontab, now runs smoothly :)
Does this app support rtx 5000 series gpus (mainly rtx 5090)?
Hi Knightchampion,
I haven't tested it with that particular card, but it should work with most modern ones. The easiest way to check would be to run the demo with the GPU option set.
I can't deny that the program is excellent. However, I'm experiencing an issue. After doing 2–3 transcriptions, the program shuts down by itself. I'm working with .mp4 files, but the problem doesn't seem to be with a specific file, because the same files that cause the program to crash work fine when I open them again
Hi abadhernan,
Thanks for your kind words, and for taking the time to report this bug. I will have a look at it and get it fixed for the next release!
Great app! it would be great if you could add a queue of files to transcribe
Hi abadhernan,
Thanks for that great suggestion, that would be very useful indeed.
Yes I am also after transcribing multiple mp3 files. I don't care if it takes a while to do so but I don't want to add file one at a time. Other than that I really like the program.
Hello! I bought the software a couple of days ago, but I am just testing it today (I replied to you on reddit!). The file that I am trying to transcribe was a DVD that I converted to mp4 with HandBrake, and clocks at about 1 hour, 20 minutes approx. 389mb.
The file is recognized by the software, and it says in the bottom "Transcribing filename.mp4". However, it doesn't go past 0%. And after 5 minutes or so, the text that says "Transcribing ..." disappears. But the progress bar still shows 0% as if there was a file loaded.
I then tried without GPU acceleration on options, and the text with the file name remains, but it still doesn't show any progress. Is that to be expected with a file of that size?
My notebooks is kind of old, a 2015 ThinkPad with an intel i7-5600U. Maybe it is expected to be that slow? It has been running for 1 hour now, and it still shows it at 0%. Maybe a way to know if it is running, or stopped and should be loaded again.
Thank you for any help! And please tell me what else should I report. Cheers!
Hi AlejoOdgers,
Thanks for your purchase!
The first thing that I would do in your case is to test with a smaller video or audio, one that is one minute for example. Just drag and drop it and see how long it takes your system to transcribe it. Most probably it will take longer than that one minute since the CPU is from 2015, so it will be much slower than a more modern machine.
Now that you know how long it roughly takes (for example double the time, or ten times, whatever it is), you will be able to get a rough idea of how long it would take on your machine to transcribe that file of 1 hour 20 minutes.
Usually I would recommend using the GPU option, but for a machine that old, probably it will cause more problems than what's worth. That's one of the reason why I added this option, to be able to skip the GPU if there are any issues. So, try it without the GPU, that's the most reliable way.
Now, after you have an idea of how long it would take, run it, and leave it there doing its thing. You can check that the application is working properly by opening up the Task Manager. You will see the name of the application and the CPU usage. You can open the Task Manager in Windows by pressing Ctrl + Shift + Esc.
I would leave it overnight running, because my guess is that it would need a few hours to process a file that is 1 hour and 20 minutes. Modern machines need about the same amount as the input, so a decade old machine would need quite a bit more.
Looks like very usefull tool.
Thanks Adeptus7!, glad you found it useful.
I found a bug (i think) in the new 241 version.
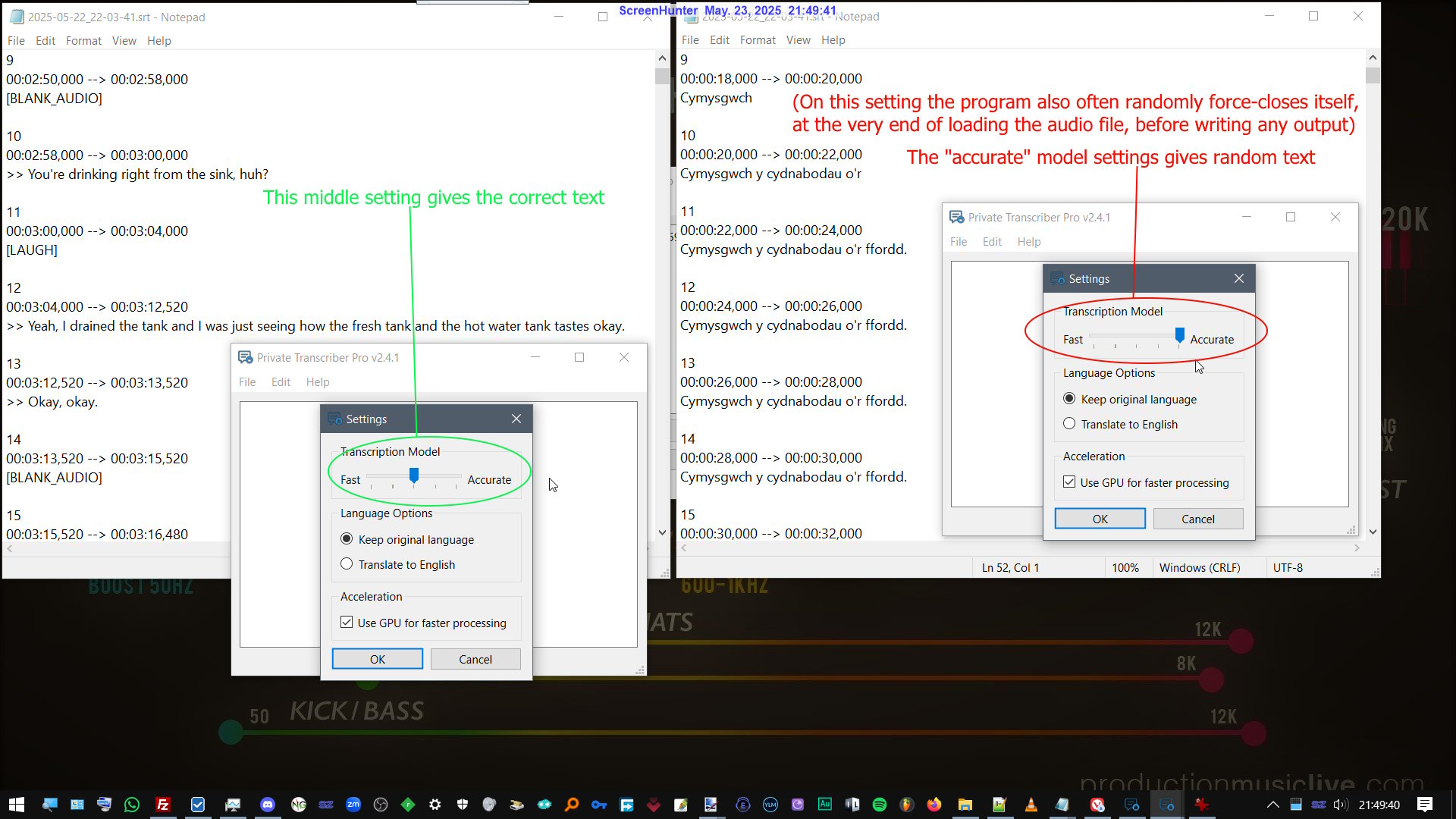
When selecting the most accurate (biggest) model, it outputs random garbage text for quite a while, then after a few minutes into the video it starts picking up the correct language, and translates it correctly.
On the default middle setting it translates the video fast and correct!
PS: on the most accurate setting it also often crashes the app at the very end of loading the video, before it begins transcribing it (.mp4 720p vids).
The video file itself is not the issue, since the middle setting does the whole video correctly without crashing.
The program has no error-log when it crashes, so I cant be helpful in providing that info, so maybe an idea to implement such a log in the future? (see image below for results)
Thanks for the detailed message.
This is something that comes from the model itself, so I will have a proper look at it. Maybe I will need to expose some extra settings that will be available as "Advanced settings" to make it work properly.
Hey! Great work!
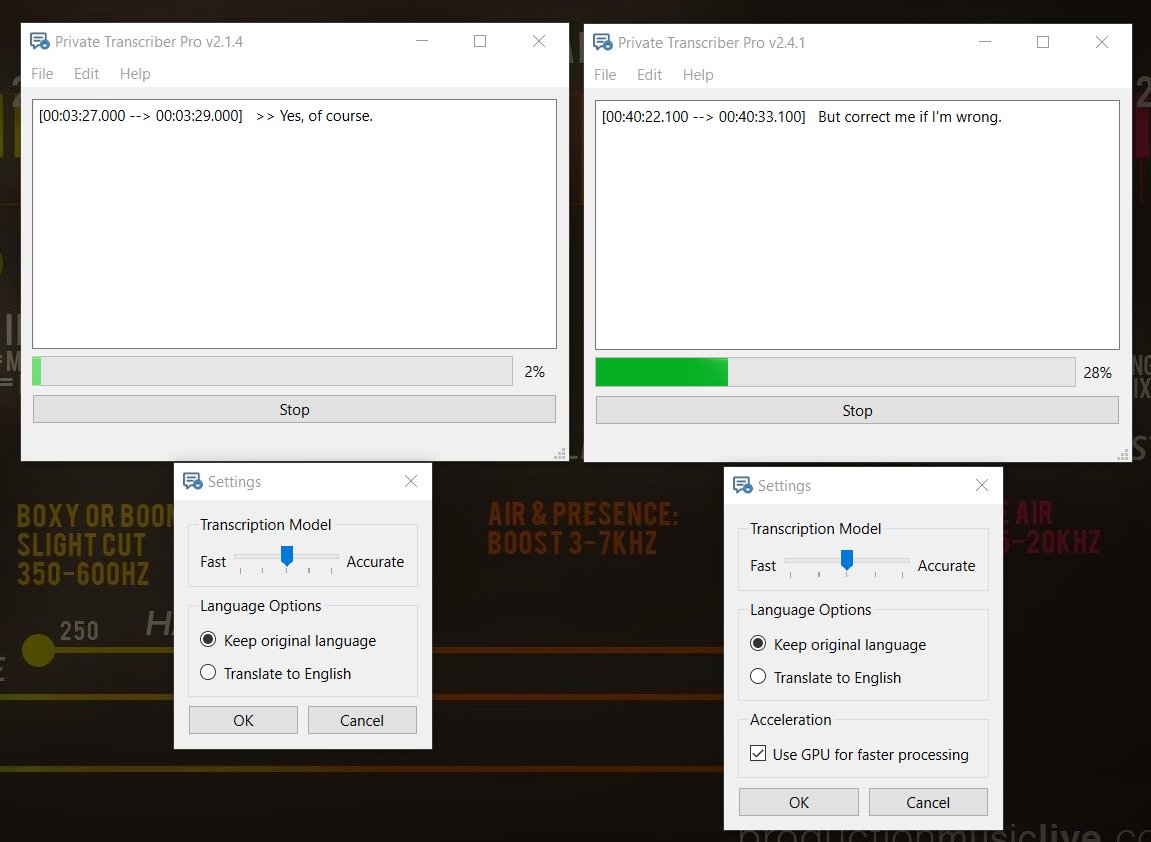
The new GPU version (v241) is waaay faster than the older (v214)
(PS: important question below the picture, so view the rest of this post)
Is it possible to have it translate to other languages than "English" ?
I assume the AI is first transcribing the audio to text in original language, then the AI translates the sentence to English also using the AI, right?
If that is the case then a dropdown list of languages the AI supports would make it possible to translate a german video into norwegian subtitles, or as now getting the german video into an english subtitle.
Can you possibly add this? Or would it be more complicated than I think?
Hi AlexData-Hawkhill,
Yeah, the GPU enabled version is much faster. Glad you got this update.
In terms of the translation, it actually doesn't work exactly like that. The model itself basically only does transcription to the same language. The model just has a "bonus" feature that allows direct translation from audio to English, no intermediary text to translate.
Having a full translation from any language to any other language is outside the scope for this app. If there's interest, I could publish an independent app that does full translation of subtitles and text from any language to any other one, which would complement this app.
An independent app that does full translation of subtitles and text from any language to any other one, is indeed very interesting!
It should of course have GPU support as well as CPU support.
It would be truly awesome if it could also have the support for converting .SRT into .VTT (WebVTT). That format has a header (3 lines) and all dots in the time-stamp unlike .SRT that has one comma in their timestamp. It also has the ability to place text at different positions on the screen, but the normal/default captions/subs position we're all used to is: align:middle size:95% line:95
The incrementing block-numbering before each block of "timestamp+position+text" as one has in .SRT, is optional in .VTT
Example (WebVTT) .VTT Subtitle/Captions File:
WEBVTT
Kind: captions
Language: en
00:00:00.000 --> 00:00:08.380 align:middle size:95% line:95
So how do you make a web page that looks like this where you have a video and it shows a
00:00:08.380 --> 00:00:14.680 align:middle size:95% line:95
nice picture where you can put the title of the video or information about what the video
00:00:14.680 --> 00:00:23.560 align:middle size:95% line:95
is about and it has obviously this video player which has this hamburger menu over here
So as you see, very similar to the .SRT format, but the benefit of this format is that it can be used with HTML5 players, so you can upload it directly to youtube (or other services supporting sub/caption) and on your own homepage, if you need video with subtitles.
PS: I've made a python script doing this .SRT to .VTT conversion, that i can share it with you, if need be. (not C++ code, but just as easy to read, he he)
Could you please add the following features: translation of SRT subtitles into other languages, an option to adjust the number of words displayed per line, and the ability to keep complete sentences on a single line if desired? Additionally, it would be great to include an AI-powered summarization function. Thank you.
Thanks firefox66 for those great suggestions!
Very nice app! Love the idea of a fast offline transcriber/translator!
I am currently testing the demo, and after doing so I paid and bought this software!
I have two questions I'd like to ask: Do you have an approx. e.t.a (month/year) for when the GPU / CPU switching possibility will arrive in an updated version?
And also I wonder if the app is temporarily writing the text it translates from speech to txt, to a txt file, like every minute or so, just in case the app might crash for unforeseen reasons. So that you may read some of it, if you have to restart the procedure due to a random app-crash?
Hi AlexData-Hawkhill,
Thanks for the kind words.
I will integrate GPU support in the next update, so it shouldn't be too long.
The app keeps the transcription in memory. In theory I could add an "autosave" of the transcription if the app is interrupted for any reason, before exiting. I could add this as well for the next update.
Nice! Looking forward to your next update!
v2.4.1 just released, which includes GPU acceleration.
Hello, i downloaded the demo, and when i import the audio file, the software shutdown unexpectedly.
Hi tok-ai, can you describe the environment, such as your OS (Windows, macOS, Linux), and the type of audio file you are using? If it's possible to share with me an audio file that is causing you this issue I could try to replicate the problem. You can msg me directly on reddit (/u/samontab)
Hi tok-ai,
This issue should now be resolved in v2.1.4 which I just released
Hi thanks for the fix! Now i can import my wav files. I also bought the transcriber and ready to begin to work.
Glad it's working for you now, all the best!
Hey Samontab ! PrivateTranscriber looks quite awesome. However, I find it very hard to evaluate with the demo version whether the app provides an accurante transcription of the audio I've submitted. Could it be possible to either A/ change the demo version to gather one every two minutes, rather than by segments of 10 secs ; or B/ to send you ONE audio file to get the full transcription ? I do have the feeling that would be more helpful to evaluate. Many thanks ! All best.
Hi LotekDotItch,
Sure!, just comment here with a link to download the audio file, or if you prefer you can send me a PM at reddit (/u/samontab)
Great, thanks !
It works! Oh wow!!!! Used it on a video from Youtube-it transcribed it correctly (saved to SRT file). THANK YOU!
I'm glad it worked for you, wtinjalanugraha :)
hi there, i just purchased, & have a question: do i load the v1.4.2 (583 MB) file in addition to the v1.5.2 file (4.6 GB)?
thanks!
Hi pityadd,
They are both completely independent versions so you only need one, v1.5.2 has more models so that's why it's larger. It includes everything you need to run it.
Enjoy your transcriptions!
thank you, it is working quite well!
why is it translating English to welsh? and copying the same thing over and over after hours of waiting for it? "Mae'n gwaith unrhyw." and other welsh phrases/sentences over and over? how do i fix this? some of the other transcripts have been fine..
Hi 19sofia99,
Since it is an AI transcription, it might not get it right all the time, and sometimes you might see what you describe.
You can try fixing it by using a different model, either a more accurate one or a faster one. You can select this in Edit->Settings under Transcription Model
Love the app, works fast and remarkably well for the processing speed! I normally use whisperx with pyannote for segmentation and diarization but that process is not well suited to rapidly transcribing video in low latency distribution! My primary use case is to scan video for obscene language prior to general distribution. The drag and drop pipeline with post processing cleanup grid has cut my worktime in half! Quick question, Is there any way to inject into the translation pipeline so I could add Speaker Diarization?
Hi tbruinsma, thanks for the nice comments!
Speaker Diarization is a frequently requested feature, and I will add it in the next update of the application. Hope that helps!
hello, i wanted to ask if this software is able to transcribe live audio- or does it only transcribe from a video file? thank you for your time!
edit: my bad, i saw that you answered this question below!
Hi,
This is fantastic, thank you for providing this. I'm deaf, tryibng to study from videos and it's driving me cray-cray!
Is there way to hook this into system sound so that I can get a rolling transcription of videos that i can'f download or get the URL of? As a student I use Learning Mangement Systems that embed videos but lock out pretty much everything except PLAY!
Google translate (Engish - to - English) is what I'm using now, but i have to pause, screen capture, Google Lens or Snagit to get text, dump in Notepad to clean out non-text, copy to asy Word or OneNote and aaarrrrgh! There has to be a simpler way!
So, can it? Or anything in the pipleine?
Hi Wad Mabbit Society, happy to hear you liked this software.
At the moment, it can only transcribe media files, not directly in real time from the microphone.
One option you can do is to record the sounds coming from your system, and then feed that recording into the software. This will get you the best quality, as real time transcription requires a simpler model, and is also not currently planned for the short term at least.
Hello, there is free trial ? Thank you
Hi rebork5555, you can download a demo of the program to see how it works. Just click on the Download button next to PrivateTranscriberPro DEMO v1.5.2.
Sorry, I didn't see the demo. I've used the demo with a spanish sound archive, but it auto translates to english. Thank you.
Hi Rebork5555, you can keep the transcription in Spanish by selecting "Keep original language" in the Settings menu.. You can see that option by going to the Edit menu, then clicking on Settings. You'll see something like this:

Sorry, I didn't see the language options. Thank you very much. I'm be able to see the original language now. Very nice software.
Am I correct to understand that the application only uses the CPU and not the GPU? Is there a way to switch between?
You are absolutely correct Kijkeenolifant, the current version only uses CPU. In a future version there will be an option to accelerate it with your GPU.
The point was to first make it available to everyone, and then making it better over time with new releases. Anyone that buys it will have access to future versions anyway, forever!
Hey Kijkeenolifant, version 2.4.1 is just released, which includes GPU acceleration for much faster transcriptions. Check it out!
Nice work on the application. Great all in one lightweight package. Would it be possible to include the larger models in the application as well? That's the only downside for me at the moment compared to installing the normal way.
Thanks Kijkeenolifant, great to hear you liked it.
What you say is a valid point. I originally planned to include all the models in the application, but ended up with a file that is way larger than itch.io's maximum allowed download file size (1GB), so I ended up including only a subset of them to make the application pass this constraint.
Having said that, it looks like I can manually request itch.io for a larger maximum file size, so I will update this tool if they increase this limit.
I ended up discovering a different way of uploading files (butler) which is much nicer and doesn't have the 1GB restriction. So, as promised, I just updated the app to include five different model sizes, which are now available in v1.5.2.
I didn't want to include all the 3 versions of the large model as the download is already at about 5GB so I only added large-v1 which seems to be the one with least amount of issues in general, but if you want to use any of the other 2 large models (v2 or v3), you can simply copy the model you want to use to the models folder and change its name to large-v1 and it will use that model instead when you select the most accurate setting.
That is amazing! Thanks for the quick turn around. I will definitely buy a copy :).